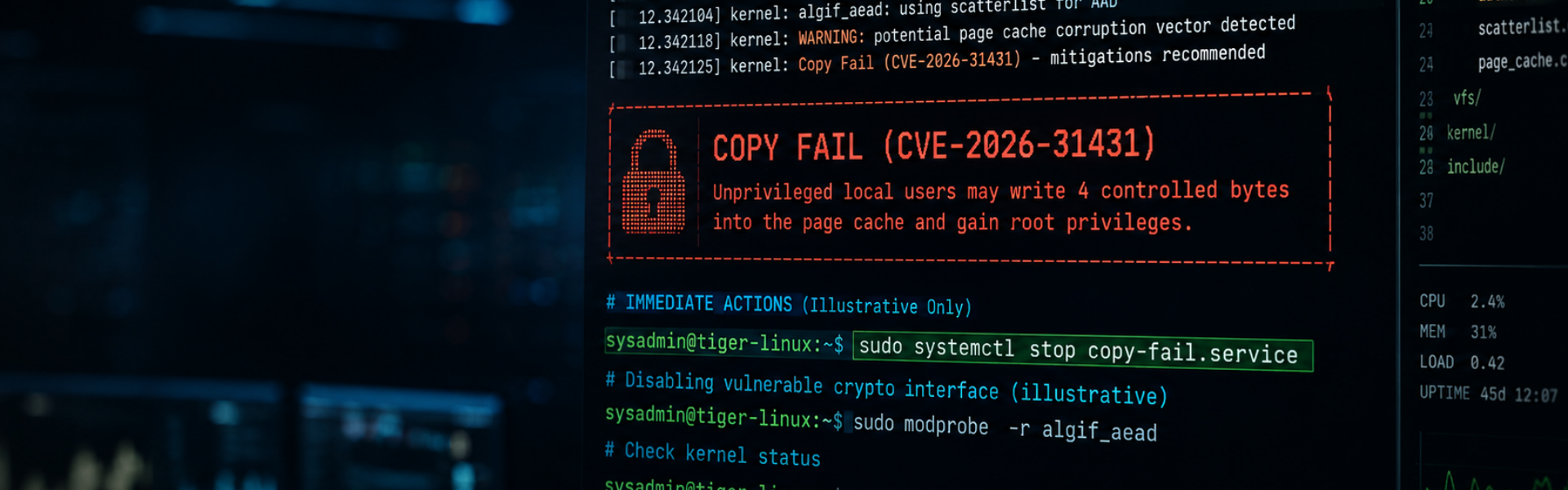
Last week’s disclosure of CVE-2026-31431, better known as “Copy Fail,” triggered one of the busiest and most disruptive weeks the Linux security community has seen in years.
Not because Linux vulnerabilities are unusual. They aren’t. Local privilege escalation (LPE) CVEs appear regularly.
What made Copy Fail different was the combination of characteristics security teams almost never see together:
- It worked reliably across nearly every major Linux distribution
- It required no race conditions or timing tricks
- The exploit was tiny, portable, and immediately usable
- It left almost no forensic trace behind
For infrastructure teams running shared Linux environments, containers, CI/CD runners, or multi-tenant platforms, this became a very real operational issue very quickly.
This article is intended as a straightforward business and technical briefing on what happened, where things stand now, and what IT leaders should be thinking about going forward.
What Is Copy Fail?
In simple terms, Copy Fail allowed an unprivileged local user to gain root access on a Linux system almost instantly.
The vulnerability exploited a flaw in how parts of the Linux kernel handled memory operations within the page cache. An attacker could overwrite four controlled bytes in memory-resident cached files; enough to manipulate trusted binaries such as /usr/bin/su without ever modifying the underlying file on disk.
Traditional security tooling often assumes that malicious changes leave traces somewhere persistent. Copy Fail largely bypassed that assumption:
- The corrupted page was never marked dirty
- Nothing was written back to disk
- Rebooting the system removed most evidence of compromise
From a defender’s perspective, that made the vulnerability unusually stealthy.
Why This Vulnerability Was Taken So Seriously
Linux kernel vulnerabilities are normally constrained by one or more limiting factors:
- Specific kernel versions
- Complex exploit chains
- Timing-sensitive race conditions
- Distribution-specific tweaks
Copy Fail has none of those constraints. The same lightweight Python exploit reportedly worked across Ubuntu, RHEL, SUSE, Debian, Amazon Linux and multiple cloud and container environments
No recompilation. No offset hunting. No distribution-specific logic.
That dramatically lowered the barrier to exploitation.
Within 72 hours of public disclosure, security firms were already reporting active exploitation attempts in:
- Shared hosting environments
- CI/CD runners
- Multi-tenant container platforms
- Development environments executing untrusted code
The Disclosure Debate
The past week has also reignited a familiar debate within the security community: how much information should be released, and when? The proof-of-concept exploit was published publicly before several major vendors had fully distributed production-ready patches.
Critics argued this gave attackers a head start. Others argued that full transparency accelerated patch adoption and forced organisations to act quickly.
Regardless of where people sit philosophically, the operational reality for IT teams was straightforward:
- assess exposure
- apply mitigations
- patch safely
- verify systems
- communicate clearly
And do it quickly.
The Hidden Operational Challenge: Mitigation vs Stability
One of the more interesting developments last week wasn’t the exploit itself. It was what happened after organisations tried to mitigate it. Many environments temporarily disabled the vulnerable algif_aead module while waiting for patched kernels.
That worked from a security perspective. Unfortunately, some organisations then discovered that specific VPN platforms, database clusters and / or hardware-accelerated encryption workflows depended on it.
This has created a challenging but very real balancing act between:
- reducing exposure
- maintaining production stability
- avoiding unexpected performance degradation
Situations like this are where specialist Linux operational knowledge becomes particularly valuable. Applying a mitigation is often the easy part. Understanding the wider behavioural impact across production systems is considerably harder.
What Copy Fail Says About Modern Linux Security
Copy Fail was discovered using AI-assisted analysis. The initial research came from human investigation, but the wider audit of the Linux crypto subsystem was reportedly scaled using AI tooling capable of identifying unusual bug classes rapidly.
That has understandably focused attention across the industry. Because if AI can identify a nine-year-old kernel flaw in roughly an hour, it raises a reasonable question: How many other “boring” parts of critical infrastructure software contain similarly dangerous edge cases?
For IT leaders, this changes the conversation slightly. Vulnerability management is no longer just about patch cadence. It’s increasingly about observability, operational readiness, vendor responsiveness, specialist platform knowledge, and understanding how infrastructure behaves under abnormal conditions
Where Things Stand Now
At the time of writing:
- Ubuntu, RHEL, and SUSE have released official patches
- Most major cloud-managed platforms have already been remediated behind the scenes
- Many unmanaged Linux instances remain vulnerable until patched and rebooted
- Older long-term support systems and embedded devices may still be awaiting backported fixes
The Linux community’s response overall has been fast, coordinated, and impressively transparent given the scale of the issue.
One of Linux’s greatest strengths has always been the speed at which the ecosystem responds collectively when serious problems emerge.
A Calm Response Matters
One thing the past week reinforced is that security incidents are rarely improved by panic.
The organisations that handled this well generally followed the same pattern:
- assess impact carefully
- prioritise genuinely exposed systems
- apply sensible mitigations
- communicate clearly
- patch methodically
- avoid creating unnecessary operational risk in the process
That sounds obvious. In practice, under pressure, it’s harder than it looks.
And this is ultimately where having experienced Linux specialists involved tends to make the biggest difference. Not because vulnerabilities can be avoided entirely – they can’t – but because calm, informed operational response reduces both technical and business risk significantly.
Copy Fail will eventually become another entry in Linux security history alongside vulnerabilities like Dirty Cow and Dirty Pipe.
But it’s also likely to be remembered as the moment many organisations realised two things simultaneously:
- modern Linux infrastructure is more critical than ever
- managing it safely now requires deeper operational expertise than many teams currently have internally
For most organisations, the challenge isn’t whether another serious vulnerability will appear. It will. The challenge is whether the right people, processes, and operational visibility are already in place before it does.
Need Advice?
If you have questions about Copy Fail, Linux patch management, or assessing exposure across your environment, feel free to contact us to discuss further.



