We’re an IT company: you’d expect us to say that we take information security seriously – and we do.
But We Would Say That, Wouldn’t We?
We don’t think you should have to take our word for it, so back in 2014 we embarked upon the journey to certification under ISO27001:2013, the Information Security standard. We examined, refined, documented and tested every aspect of Information Security, both within Tiger Computing and extending to how we manage and support our clients’ systems. In May 2015, we put ourselves to the test. We were independently audited and were assessed and certified as meeting the requirements of ISO27001:2013.
What Does This Mean For You?
It means that you can rest assured that we take Information Security seriously; that we will continue to refine and improve our Information Security policies; and that we will be independently audited annually to confirm that we are maintaining the required high standards of ISO27001:2013.
What’s Next?
We will continue to grow our support, management and monitoring infrastructure to ensure that our clients have the very best availability of your systems – and we’ll continue building our team of the best Linux experts in the UK.
Technical support from dedicated Linux experts
Email Support
Telephone Support
Regular Security Updates
Between 09:00 – 17:00, Monday to Friday
Between 17:00 - 18:00, Monday to Friday
Between 18:00 and 19:00, Monday to Friday, or by arrangement
Response Time for Critical Issues
1 hour
10 minutes
Priority Response
24/7 Proactive System Monitoring i
24/7 Proactive System Monitoring
System Monitoring
Effective system monitoring, with automated alarm notifications to support staff, can preempt many problems and thus improve system availability. Such monitoring will typically include:
Free diskspace available
CPU utilisation
Memory utilisation
RAID health
Checking for disk errors
Checking system logs for potential problems
Ensuring essential services are running
The status of the backups
Whether security updates need to be installed
Routine system security checks
Checking the validity and lifetime of any SSL certificates be installed
Routine system security checks
Checking the validity and lifetime of any SSL certificates
Business Process Monitoring
It is relatively trivial to extend the monitoring to cover key business processes. For example, an online shop may know that, on average, it takes 10 orders an hour. One check might be to look at the time of the last update of the “sales” table in the database. If it was more than 10 minutes ago, an alarm could be raised.
This is by no means the only test that should be run on such a server, and it wouldn’t be very helpful in diagnosing the cause of the problem. It would, however, alert staff who could check that all is well. If an issue is found, it may be appropriate to add further checks to more quickly identify future similar issues.
The point is that IT is there to support the business. Monitoring its effectiveness in doing so is a worthwhile approach.
Trend Monitoring i
Trend Monitoring
While status monitoring is helpful in identifying problems when they begin to make themselves apparent, system trend monitoring is concerned with looking at various system parameters over a longer period of time. Typically, many of the same parameters are measured, but are displayed as graphs. This is useful in allowing:
reasonable predictions to be made
the cause of transient issue to be narrowed down.
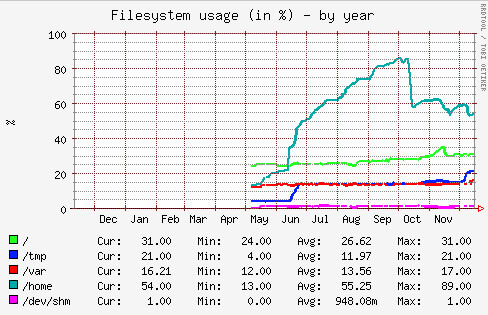
Predictions
By way of example, the graph below shows the disk usage of a system over time. It can be seen that the /home partition (the top line) was filling up between June and early October. The system status monitor alerted support staff to the fact that the disk was getting full, and the graph below enabled a judgement to be made that, unless something was done, the system would run out of space in about two months’ time. In this particular case, some files that were no longer required were deleted, shown by the drop in mid- October, but it would have been possible to schedule the fitting of an additional or larger disk if that had been appropriate. The important point is that action was taken pro-actively rather than reactively.
Configuration Management i
Configuration Management
The configuration of every server we support is stored on a central Configuration Management server.
Each server checks its configuration against the master server periodically. If the actual configuration of the client server differs from that defined on the master, the necessary changes are made on the client to bring it into line.
It is possible, for example, to ensure that certain software is installed (or even that it is not installed), or that certain user accounts are or are not present on all or a defined subset of servers.
This ensures consistency between the servers as required, and makes the building of another server “just like server X” very easy. It also makes it easy to manage configuration changes across multiple servers in a consistent and controlled manner.
Unlimited Incidents Per Month i
Unlimited Incidents Per Month
You shouldn’t have to report any server problems to us – we should know about them before you – but we certainly aren’t going to impose any limit on you reporting issues.
The business model of an “allowance” of incidents per month, with an additional charge for any incidents over that allowance, is not one we subscribe to.
We work hard to stop things going wrong in the first place rather than waiting until they break.
System Tuning i
System Tuning
Effective system monitoring can also be used to improve system performance. The following example considers a web server that uses a MySQL database; however, the principle applies equally to other areas of system performance. Here, the trend graphs are used to monitor the impact of the changes that were made.
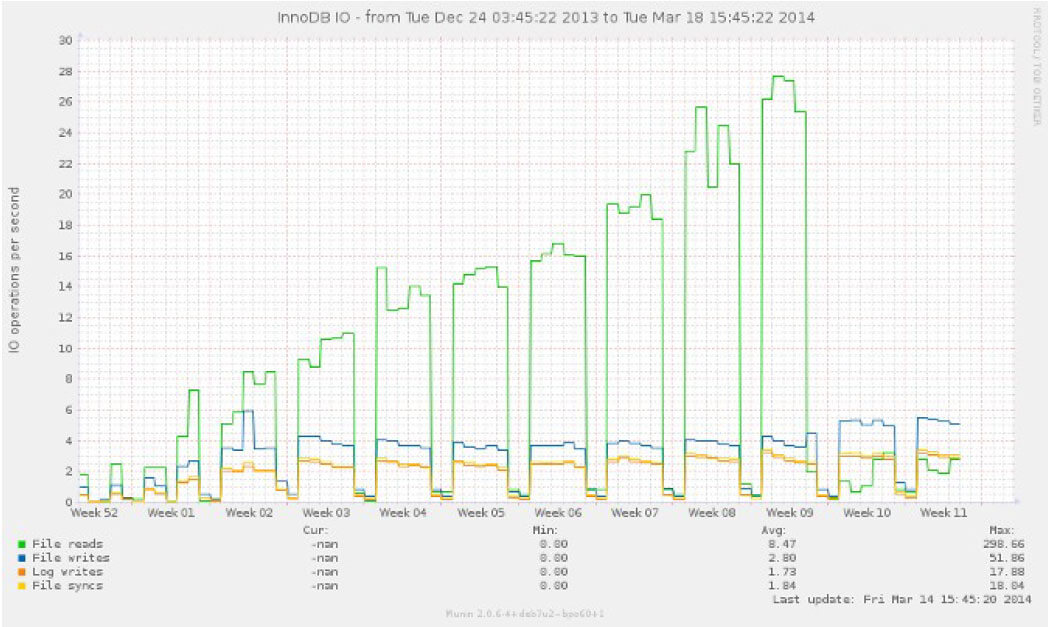
After examining the system, the decision was made in week 9 to change a number of MySQL parameters relating to caching (in other words, keeping more of the database in memory). In the graph below, a dramatic reduction in disk reads and writes can be seen because less data needs to be moved to and from the disk:
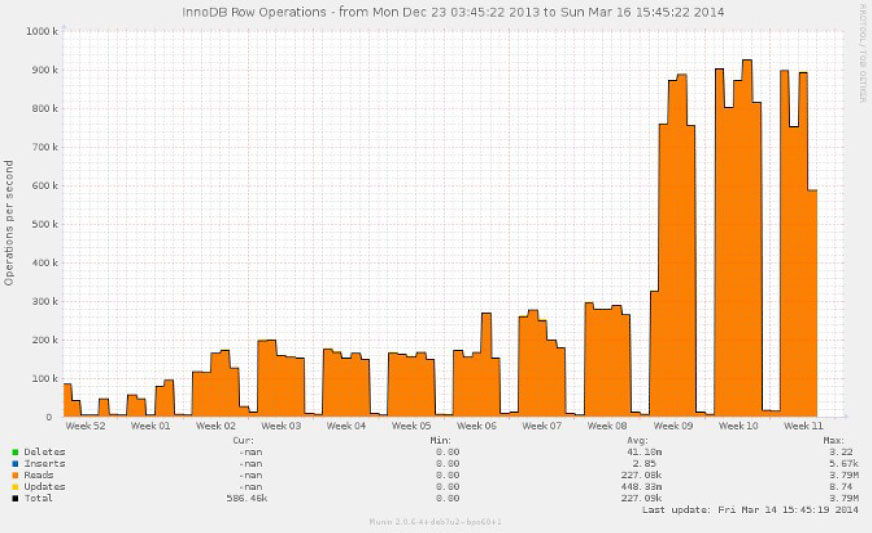
As a consequence of more database operations taking place in memory rather than requiring disk access, the number of database operations per second has tripled:
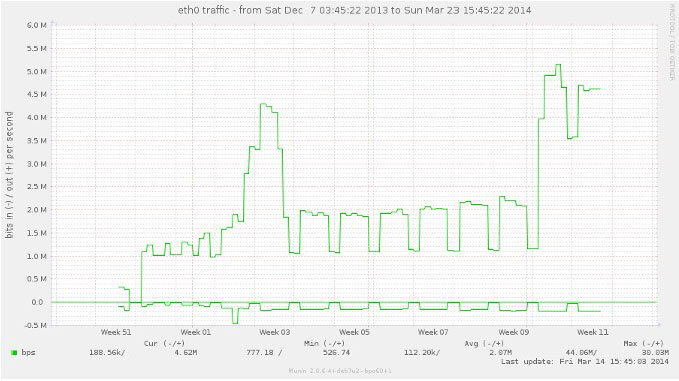
Below, it can be seen that the network traffic on the web server has increased significantly after week 9. This is because the database is now working faster, and is able to handle more page requests. (The additional network traffic in week 3 was unrelated to this work, and not typical of this application’s normal performance.)
Operating System Upgrades i
Operating System Upgrades
We include operation system version upgrades as a standard component of all of our support contracts.
It’s important that your servers are kept up to date and secure, and we believe that operating system upgrades should be an integral part of the service, not a paid-for extra.
Between 09:00 – 17:00, Monday to Friday
Between 08:00 - 20:00, Monday to Friday
Between 08:00 – 20:00, Monday to Friday, or by arrangement
User Data Backups i
User Data Backups
User data backup is available as an additional service. We use online backups to two independent remote backup servers. These are hosted in geographically disperse data centres, and each backup is independent (we back the data up twice rather than copying data from one backup server to another). Each backup includes a customisable preparation phase where, for example, databases may be dumped or custom application functions may be called. Each backup is monitored, checking that:
the last backup completed without errors
the last backup is not too old
the current backup has not been running too long
Optional Extra
Optional Extra
Optional Extra
Most Popular Package
Customizable Support Packages
While our support levels provide a comprehensive starting point, we understand that every business has unique needs. Our Business and Premier support packages can be customized to align with your specific operational requirements, ensuring you get the exact level of support you need.
Compliance and Certification:
ISO27001 certified, ensuring compliance with the highest security standards in the industry.
We’ve been relying on Tiger Computing for our Linux support for a few years now. They are an absolute dream to work with: highly knowledgeable, friendly and extremely competent.
IT support done the way it should be.
– Dr Ross Fraser, Head of Bioinformatics at Synpromics Ltd
Enquire about our Linux Support Packages
Contact us to discuss any of our Linux Support packages in further detail.